Inhalt dieses Topics
Grundlagen
Die Regelbasierte Vergabe (RB) ist eine Methode in plusmeta zur Metadatenvergabe.
Bei der Regelbasierten Vergabe wird der Text mit der in den Metadaten definierten Werteliste abgeglichen. Wird ein Treffer gefunden, bekommt dieser Punkte. Der Treffer mit den meisten Punkten gewinnt und wird zugewiesen.
Wie viele Punkte vergeben werden hängt davon ab, wo der Treffer gefunden wurde. Neben den Bezeichnungen (Labels) der Listenwerte können auch Indikatoren hinterlegt werden. Darüber hinaus können auch Teiltreffer Punkte bekommen. Die Häufigkeit des Auffindens wird kaum berücksichtigt.
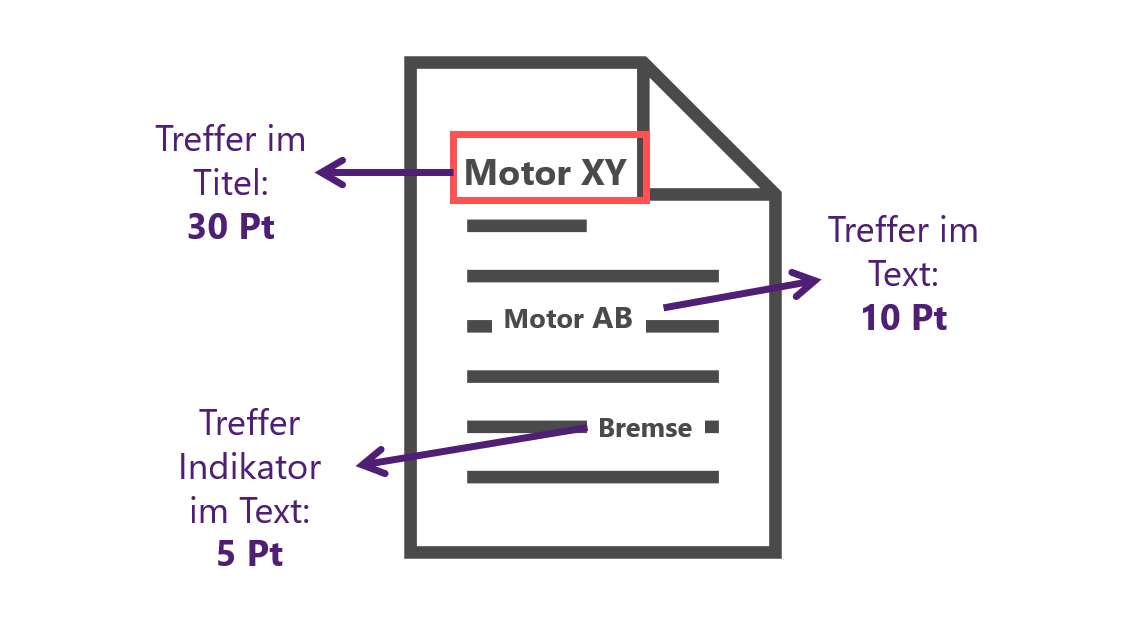
Für die jeweils zu vergebenden Punkte gibt es in plusmeta Standardwerte. Sie sind aber auch individuell konfigurierbar.
Indikatoren
Indikatoren spielen bei der Regelbasierten Vergabe eine wichtige Rolle. Als Indikatoren können Wörter oder Zeichenketten hinterlegt werden, die Hinweisgeber für die Zuweisung bestimmter Metadatenwerte sind. Indikatoren können Synonyme sein, alternative Schreibweisen oder sonstige Hinweisgeberwörter, die in den Texten typischerweise vorkommen. Werden Indikatoren in Texten gefunden, fließen die Treffer ebenfalls in die Punktevergabe ein. Für die Punktevergabe für Indikatortreffer kennt plusmeta Standardwerte. Wie viele Punkte Indikatoren und Teile von Indikatoren bekommen, kann darüber hinaus auch individuell konfiguriert werden.
Weitere Informationen zu Indikatoren finden Sie hier.
Regelbasierte Vergabe anpassen
Die Regelbasierte Vergabe orientiert sich an Regeln, die konfigurierbar sind. Die Konfiguration erfolgt über ein Konfigurationsobjekt. Gibt es kein spezielles Konfigurationsobjekt, werden die Standardregeln angewendet.
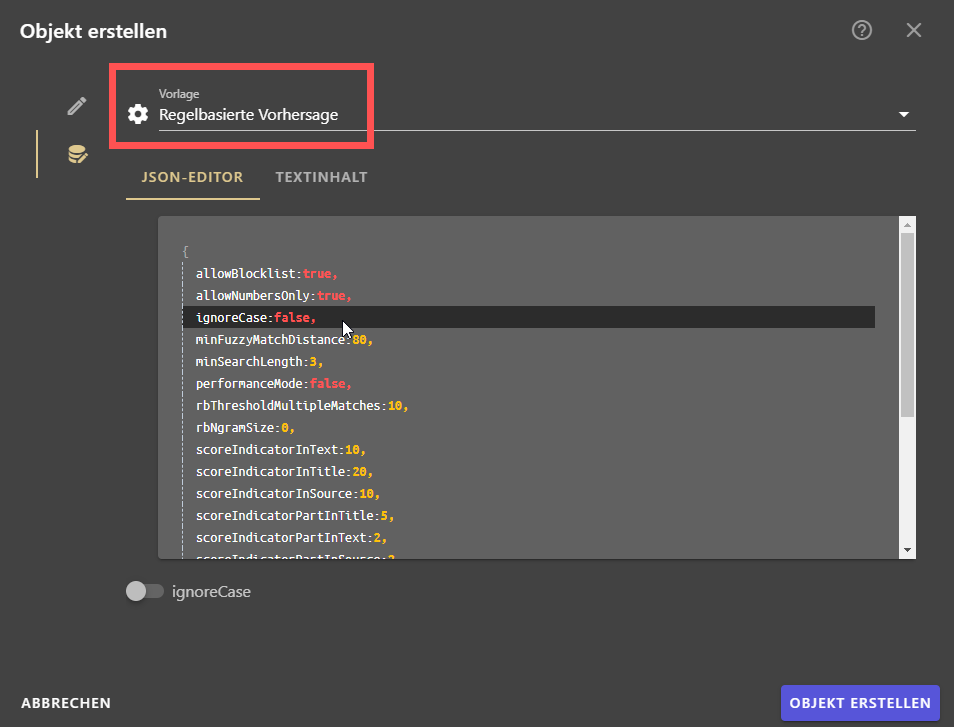
Konfigurationsobjekt erstellen
Mithilfe eines Konfigurationsobjekts können die Standardwerte der regelbasierten Vergabe angepasst werden.
- Die Objekte-Ansicht öffnen.
- Auf die Hinzufügen-Schaltfläche klicken, um ein neues Objekt zu erstellen.
- Den Objekttyp Konfigurationsobjekt auswählen.
- Den unteren Reiter des Objekt erstellen-Dialogs öffnen.
- Die Vorlage Regelbasierte Vorhersage auswählen.
Info: Wird bei der Erstellung keine Vorlage gewählt, kann diese später auch nicht mehr ergänzt werden.
- Im JSON-Editor die gewünschten Werte anpassen.
- Auf OBJEKT ERSTELLEN klicken.
Konfigurationsobjekt aktivieren
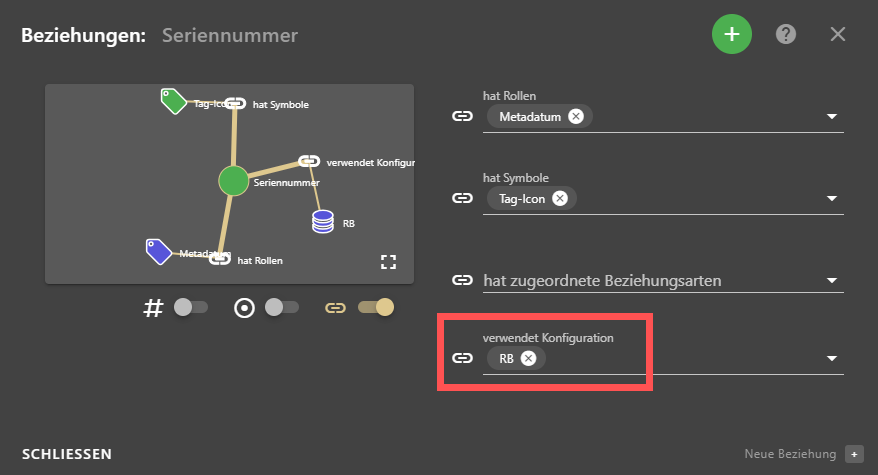
- In die Eigenschaften-Ansicht klicken.
- Metadatum auswählen, dem sie das Konfigurationsobjekt zuweisen möchten.
- Auf die Schaltfläche klicken, um den Eigenschaft bearbeiten-Dialog zu öffnen klicken. Der Eigenschaften bearbeiten-Dialog öffnet sich.
- Den Bereich Beziehungen öffnen.
- Auf die Hinzufügen-Schaltfläche klicken, um eine Beziehung hinzuzufügen.
- Die Beziehung verwendet Konfiguration aus der Drop-Down-Liste auswählen.
- Im Feld verwendet Konfiguration aus der Drop-Down-Liste das Konfiguartionsobjekt auswählen.
- Auf SCHLIESSEN klicken.
Die Änderungen werden automatisch gespeichert.
Parameter Konfiguration
| Angabe | Werte | Funktion | Standartwert |
|---|---|---|---|
allowBlocklist |
True / false |
Blocklist erlauben / ignorieren. Beispiel: „ist“ und Unternehmen mit Produktreihe „IST“ | true |
allowNumbersOnly |
True / false |
True = Auch reine Zahlenwerte werden ausgewertet ; False = Reine Zahlenwerte werden nicht ausgewertet | true |
ignoreCase |
True / false |
Groß- und Kleinschreibung ignorieren bzw. berücksichtigen | false |
minFuzzyMatchDistance |
%-Angabe (ohne %-Zeichen) | Gibt die Mindestübereinstimmung für Fuzzy Matches an. Fuzzy Matches werden mit diesem Wert multipliziert. Dadurch fällt der Score von Fuzzy Matches geringer aus. | 80 |
minSearchLength |
Zahl von 0 – x | Gibt die Mindestlänge der durchsuchten Zeichenketten an z. B. Indikatoren, die nur 2 Zeichen haben, werden nicht gefunden, wenn 3 eingestellt ist. | 3 |
performanceMode |
True / false |
Stellt Fuzzy Matches aus | false |
rbThresholdMultipleMatches |
%-Angabe | Stellt Fuzzy Matches aus | false |
rbNgramSize |
Zahl | Gibt an, wie viele Wörter die Wortgruppen bei der Zerlegung des Texts in Tokens enthalten, z. B. bestehen die Tokens bei der Angabe „1“ aus einzelnen Wörtern, bei der Angabe „2“ aus Wortpaaren, usw. Sobald Mehrwort-Tokens erzeugt werden (Angabe „2“ und mehr), werden immer zusätzlich 1-Wort-Tokens erzeugt. Wird die Angabe negiert, z. B. „-3“, dann wir auch jeder Zwischenschritt erzeugt (1-, 2- und 3-Wort-Tokens). | 0 |
scoreIndicatorInText |
Punktewert 0 – x | Punktzahl für Treffer eines Indikators im Text | 10 |
scoreIndicatorInTitle |
Punktewert 0 – x | Punktzahl für Treffer eines Indikators im Titel | 20 |
scoreIndicatorInSource |
Punktewert 0 – x | Punktzahl für Treffer eines Indikators in einer Metadaten-Quelle | 10 |
scoreIndicatorPartInTitle |
Punktewert 0 – x | Punktzahl für Treffer eines Indikator-Teils im Titel | 5 |
scoreIndicatorPartInText |
Punktewert 0 – x | Punktzahl für Treffer eines Indikator-Teils im Text | 2 |
scoreIndicatorPartInSource |
Punktewert 0 – x | Punktzahl für Treffer eines Indikator-Teils in einer Metadaten-Quelle | 2 |
scoreLabelInText |
Punktewert 0 – x | Punktzahl für Treffer eines Labels im Text | 55 |
scoreLabelInTitle |
Punktewert 0 – x | Punktzahl für Treffer eines Labels im Titel | 85 |
scoreLabelInSource |
Punktewert 0 – x | Punktzahl für Treffer eines Labels in einer Metadaten-Quelle | 85 |
scoreLabelPartInText |
Punktewert 0 – x | Punktzahl für Treffer zu einem Label-Teil im Text | 10 |
scoreLabelPartInTitle |
Punktewert 0 – x | Punktzahl für Treffer zu einem Label-Teil im Titel | 30 |
scoreLabelPartInTitle |
Punktewert 0 – x | Punktzahl für Treffer eines Label-Teils in einer Metadaten-Quelle | 30 |
tokenSplitPattern |
RegEx | Regulärer Ausdruck für die Zerlegung der Texte in Tokens | (?:[^_\.,:"\[\]\(\)\s]+[\.,:]?)+ |
tokenContext |
RegEx | Definiert den Kontext (Zeilenende, Prefix, Labels usw.) | tokenContext: { } |
Regelbasierte Erkennung mit Kontextabhängigkeit konfigurieren
Die Regelbasierte Erkennung kann mithilfe eines Kontexts auf einen bestimmten Textbereich eingeschränkt werden. Das ist besonders hilfreich, wenn Listenwerte eines Metadatums auch an anderen Stellen im Dokument vorkommen.
Beispiel: Das Metadatum “Material Gehäuse” hat die Werte “Metall” und “Plastik”, gesucht ist “Metall”. Im Dokument wird aber auch das Material für die “Steckverbindung” angegeben (“Plastik”).
Ohne Kontext würden beide Listenwerte für “Material Gehäuse” die gleiche Punktzahl erhalten, da beide Listenwerte im Text vorkommen. Mit einem konfigurierten Kontext lässt sich die Erkennung auf den relevanten Bereich beschränken.
Die benötigten Parameter für den Kontext befinden sich unten im Konfigurationsobjekt unter tokenContext:
| Angabe | Werte | Funktion | Standartwert |
|---|---|---|---|
afterPrefix |
RegEx | RegEx, der hinter das Präfix geschrieben wird. Das Präfix ist entweder das Label, die Indikatoren oder beides. | [\s:\.]* |
afterValue |
RegEx | RegEx, der das Ende des Kontexts markiert. Der Standardwert “$” setzt einen Kontext bis ans Zeilenende. | $ |
convertNewlineToSpace |
true / false |
Bestimmt, ob Umbrüche zu Leerzeichen konvertiert werden sollen. Für einen zeilenbasierten Kontext muss false gesetzt sein. |
false |
enableRbContext |
true / false |
Dieser Wert muss auf true gesetzt sein, damit der Kontext für die regelbasierte Erkennung aktiviert wird. |
false |
includeIndicators |
true / false |
Bestimmt, ob für das Präfix Indikatoren verwendet werden sollen. | true |
includeLabels |
true / false |
Bestimmt, ob für das Präfix Labels verwendet werden sollen. | true |
multiLine |
true / false |
Bestimmt, ob Zeilenanfang und -ende gematcht werden können. Für einen zeilenbasierten Kontext muss true gesetzt sein. | true |
plus:Class |
RegEx | RegEx, der zwischen den Listenwert (Value) und afterValue geschrieben wird. Dieser Wert bestimmt in Kombination mit afterValue, wie groß der Kontext gezogen wird. | .* |