Inhalt dieses Topics
- Überblick über die Vergabemethoden
- Linguistische Verfahren (LG / L2)
- Regelbasierte Vergabe (RB)
- Mapping (MP)
- Machine Learning (ML)
- Large Language Model (LLM)
- Extraktor (EX)
- Zusammengesetzte Metadaten
Die Künstliche Intelligenz in plusmeta setzt sich aus unterschiedlichen Methoden zur Metadatenvergabe zusammen. Für jedes Metdatum kann durch Konfiguration die passende Methode ausgewählt werden. Die Methoden sind auch kombinierbar.
Die meisten Vergabemethoden sind auf Text angewiesen. Dieser Text wird aus verschiedenen Quellen eines Dokuments / Content Moduls extrahiert. Mehr dazu finden Sie auf der Hilfeseite Metadatenquellen.
Überblick über die Vergabemethoden
| Kürzel | Bezeichnung | Beschreibung |
|---|---|---|
| LG | Linguistisches Verfahren | Spezielles Verfahren zum Erkennen der Sprache. |
| L2 | Linguistisches Verfahren 2 | Neues Konzept für die Spracherkennung. Unterstützt mehr Sprachen als LG und zeigt in der Anwendung oft bessere Ergebnisse. |
| RB | Regelbasierte Vergabe | Vergabe auf Basis von Regeln zu im Text gefundenen Indikatoren. |
| MP | Mapping | Vergabe über definierte Beziehungen zwischen Metadaten (Knowledge Graph). |
| ML | Machine Learning | Vorhersage der Metadaten mithilfe eines trainierten KI-Modells. |
| LLM | Large Language Models | Extraktion der Metadaten mithilfe eines Large Language Models (LLM). |
| EX | Extraktor | Werte-Extraktion anhand definierter Muster. |
| HE | Heuristische Extraktion | Spezielles Vorgehen zum Ermitteln des vermuteten HTML- bzw. PDF-Titels. |
| GL | Guide Line / Projekt-Vorgabe | In den Einstellungen des Projekts können Metadaten festgelegt werden, die an alle im Projekt enthaltenen Objekte vergeben werden sollen. |
| - | Eingelesene Metadaten | In der Quelldatei bereits vorhandene Metadaten werden eingelesen, wenn in plusmeta eine passende Konfiguration vorliegt. |
| - | Zusammengesetze Metadaten |
In den folgenden Abschnitten wird die Funktionsweise der wichtigsten Vergabemethoden kurz erklärt.
Linguistische Verfahren (LG / L2)
Die linguistischen Verfahren werden ausschließlich zur Erkennung der Sprache eingesetzt. Für die Erkennung der Sprache gibt es in plusmeta zwei spezifische Verfahren. Über ein Konfigurationsobjekt ist die Methode auswählbar.
Regelbasierte Vergabe (RB)
Bei der Regelbasierten Vergabe wird der Text mit der in den Metadatendaten definierten Werteliste abgeglichen. Wird ein Treffer gefunden, bekommt dieser Punkte. Der Treffer mit den meisten Punkten gewinnt und wird zugewiesen.
Wie viele Punkte vergeben werden hängt davon ab, wo der Treffer gefunden wurde. Neben den Bezeichnungen (Labels) der Listenwerte können auch Indikatoren hinterlegt werden. Darüber hinaus können auch Teiltreffer Punkte bekommen.
Für die jeweils zu vergebenden Punkte gibt es in plusmeta Standardwerte. Sie sind aber auch individuell konfigurierbar.
Weitere Informationen zur Regelbasierten Vergabe finden Sie hier.
Mapping (MP)
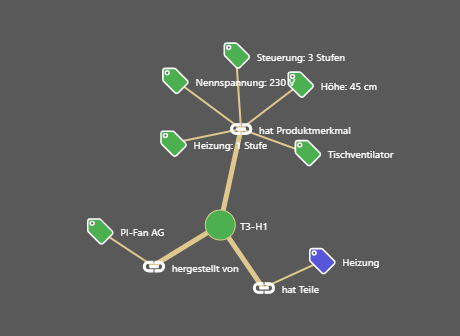
Bei Mappings wird ein Wissensnetz mit Abhängigkeiten zwischen Metadaten definiert. Dieses Wissensnetz kann regelbasiert ausgewertet und für die Metadatenvergabe genutzt werden: Wenn ein bestimmter Wert “A” als Metadatum vergeben wurde, dann soll auch der abhängige Wert “B” mitvergeben werden.
Ein Beispiel ist die Auswertung der Herstellerbeziehung zwischen den Metadaten „Produkt“ und „Hersteller“. Über ein kleines Produktmodell kann hier ausgedrückt werden, welcher Hersteller welche Produkte hergestellt. Wird dann das Produkt (z.B. “T3-B”) im Text gefunden, wird auch der Hersteller (z.B. “PI-Fan AG”) als Metadatum mitvergeben werden.
Auf diese Weise können auch die Produktmerkmale von Produktvarianten behandelt werden oder die Zuweisungen aus veralteten Metadatenkonzepten in neue transformiert werden.
Weitere Informationen zum Metadaten-Mapping finden Sie hier
Machine Learning (ML)
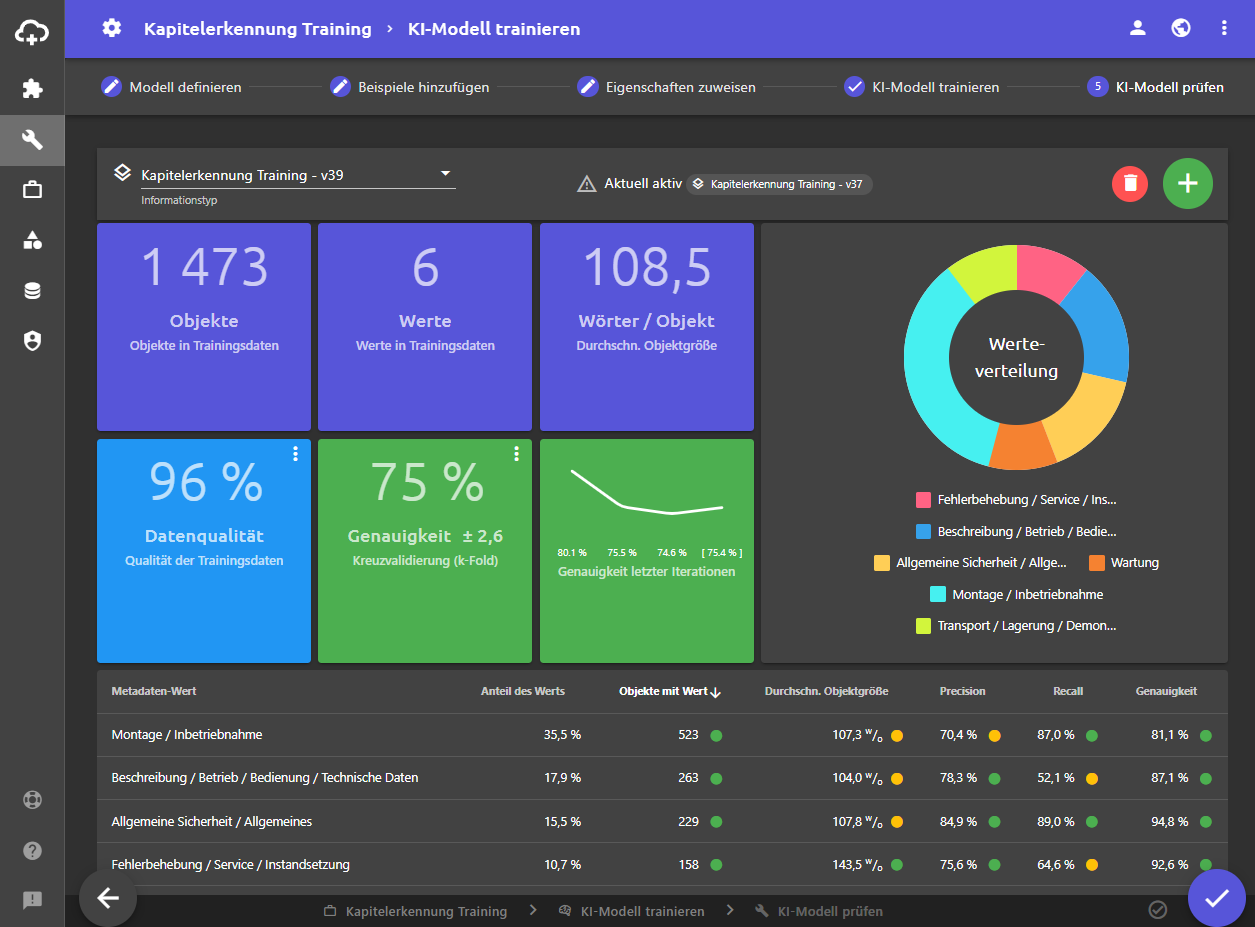
Beim Machine Learning werden die Metadaten auf Basis eines trainierten Modells vergeben. Für jedes Metadatum wird dabei ein Modell benötigt. In plusmeta gibt es einen speziellen Workflow, der Sie durch das Modelltraining führt.
Damit ein gutes Modell entstehen kann, ist für jeden zu vergebenden Wert eine kritische Mindestmenge von ca. 20 Beispielen nötig. Im Training wird die KI mit manuell mit Metadaten versehenen Beispielen gefüttert. Im Hintergrund entsteht ein Modell. Dieses Modell nutzt plusmeta dann für die Metadatenvergabe.
Die Qualität und Genauigkeit des Modells kann in plusmeta anhand von Kennzahlen bewertet werden.
Weitere Informationen zum Machnine Learning finden Sie hier.
Large Language Model (LLM)
Bei der LLM-Metadatenvergabe werden große Sprachmodelle (LLMs) verwendet, um Metadaten, beispielsweise technische Daten, wie Maße oder Gewicht, aus Texten zu extrahieren oder umfangreiche Dokumentationen zusammenzufassen.
Weitere Informationen zum Machnine Learning finden Sie hier.
Extraktor (EX)
Bei Extraktoren handelt es sich um so genanntes “Pattern Matching”. Über einen regulären Ausdruck wird ein Suchmuster definiert, z. B. eine spezifische Zeichenkette und Format: “Seriennummer: xx-xxx-xxx”.
plusmeta durchforstet den Text nach Stellen, die zu dem Muster passen und extrahiert den vorgegebenen Teil, z. B. 12-345-678 und schreibt diesen ins Metadatenfeld.
Extraktoren werden über eine Konfiguration am Metadatum und ein Konfigurationsobjekt eingerichtet.
Weitere Informationen zu Extraktoren finden Sie hier.
Zusammengesetzte Metadaten
Mit zusammengesetzten Metadaten können Metadatenwerte verschiedener Metadaten zu einem neuen Metadatum zusammengesetzt werden. Dazu können Filter, Substrings und Fallback-Werte genutzt werden. Die erzeugten Zeichenketten können wiederum als Eigenschaften in plusmeta angelegt werden.
Weitere Informationen zu zusammenesetzte Metadaten finden Sie hier.