Quellen für die Metadatenerkennung
Es gibt verschiedene Quellen innerhalb eines Objekts, in denen plusmeta Metadaten finden kann. Je nach Konfiguration kann es sinnvoll sein, die Quellen möglichst gezielt einzuschränken.
Für die KI-Methoden Regelbasierte Vergabe und Extraktoren kann die Metadatenquelle im Parameter scope festgelegt werden.
| Art | Erklärung | “scope”-Parameter | Beschreibung |
|---|---|---|---|
| Text | Textinhalt der Datei | text |
Der Text des hinzugefügten Objekts wird beim Import extrahiert, wobei erste Analysen stattfinden. Der extrahierte Text kann im Textinhalt-Dialog eingesehen werden. |
| Titel | Dateiname, PDF-Titel, Inhalt title-Tag, Inhalt h1-Tag, etc. | title |
Was für plusmeta als “Titel” gewertet wird, ist über die Systemrolle “Titel-Eigenschaft” konfigurierbar. Standardmäßig extrahiert plusmeta den Dateiname, Dokument-Metadaten mit Titel-Charakter wie etwa den PDF-Titel oder Titel-Elemente aus HTML-Dateien. |
| Quelle für Metadatenerkennung | Verzeichnispfad, Schlagworte aus Dokument-Metadaten, HTML-Metadaten, etc. | source |
Über die Systemrolle “Quelle für Metadatenerkennung” können weitere Eigenschaften und Metadaten am Dokument zu dieser Metadatenquelle hinzugefügt werden. Diese werden dann bei der Metadatenerkennung ebenfalls von der KI berücksichtigt. Der Verzeichnispfad ist eine sinnvolle Metadatenquelle, wenn ganze Verzeichnisse importiert werden. |
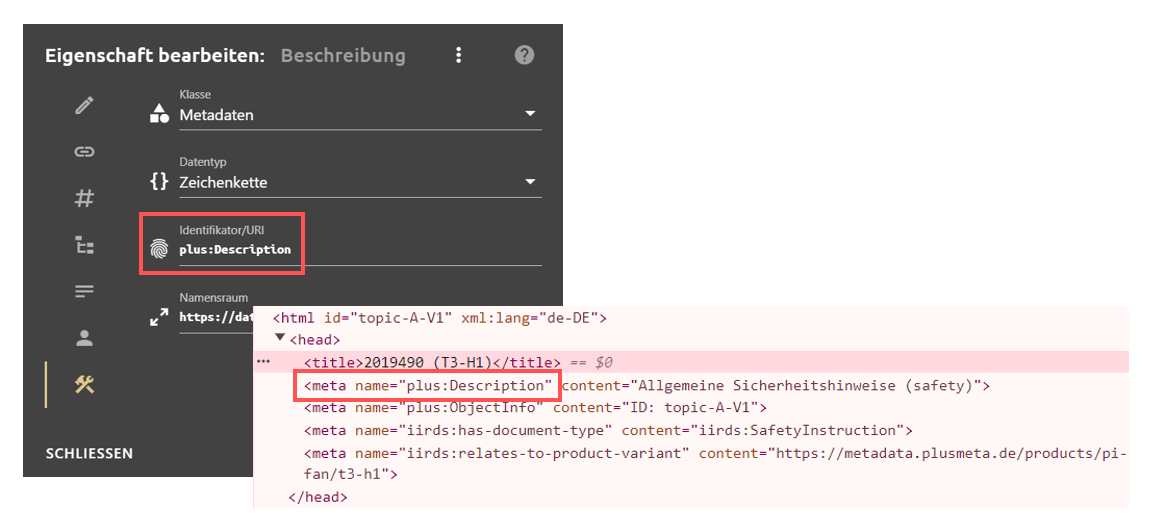
| Identifikator | Identifikator eines Metadatums | z. B. [plus:Summary] |
Der Metadatenwert eines Metadatums kann als Quelle für ein anderes Metadatum verwendet werden (z. B. einen Extraktor auf eine LLM-Zusammenfassung anwenden). |
Vorhandene Metadaten im Workflow-Schritt: Inhalte hinzufügen
Vorhandene PDF- oder HTML-Metadaten, inklusive Dateimetadaten werden oft als Metadatenquelle verwendet.
- In den ersten Workflow-Schritt Inhalte hinzufügen gehen und ggfs. Objekte hinzufügen.
- Auf das Zahnrad klicken und die Spalte Metadaten einblenden.
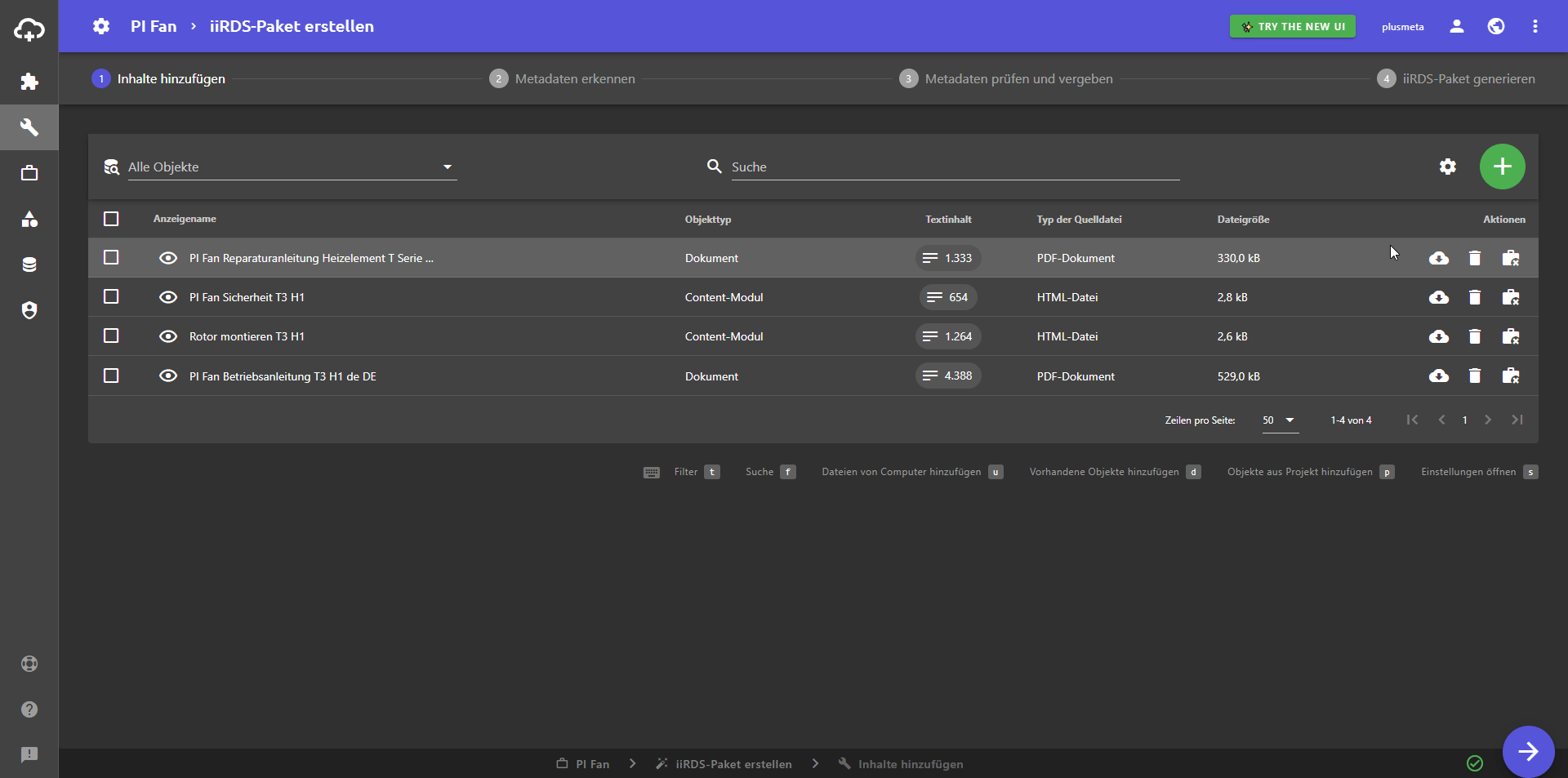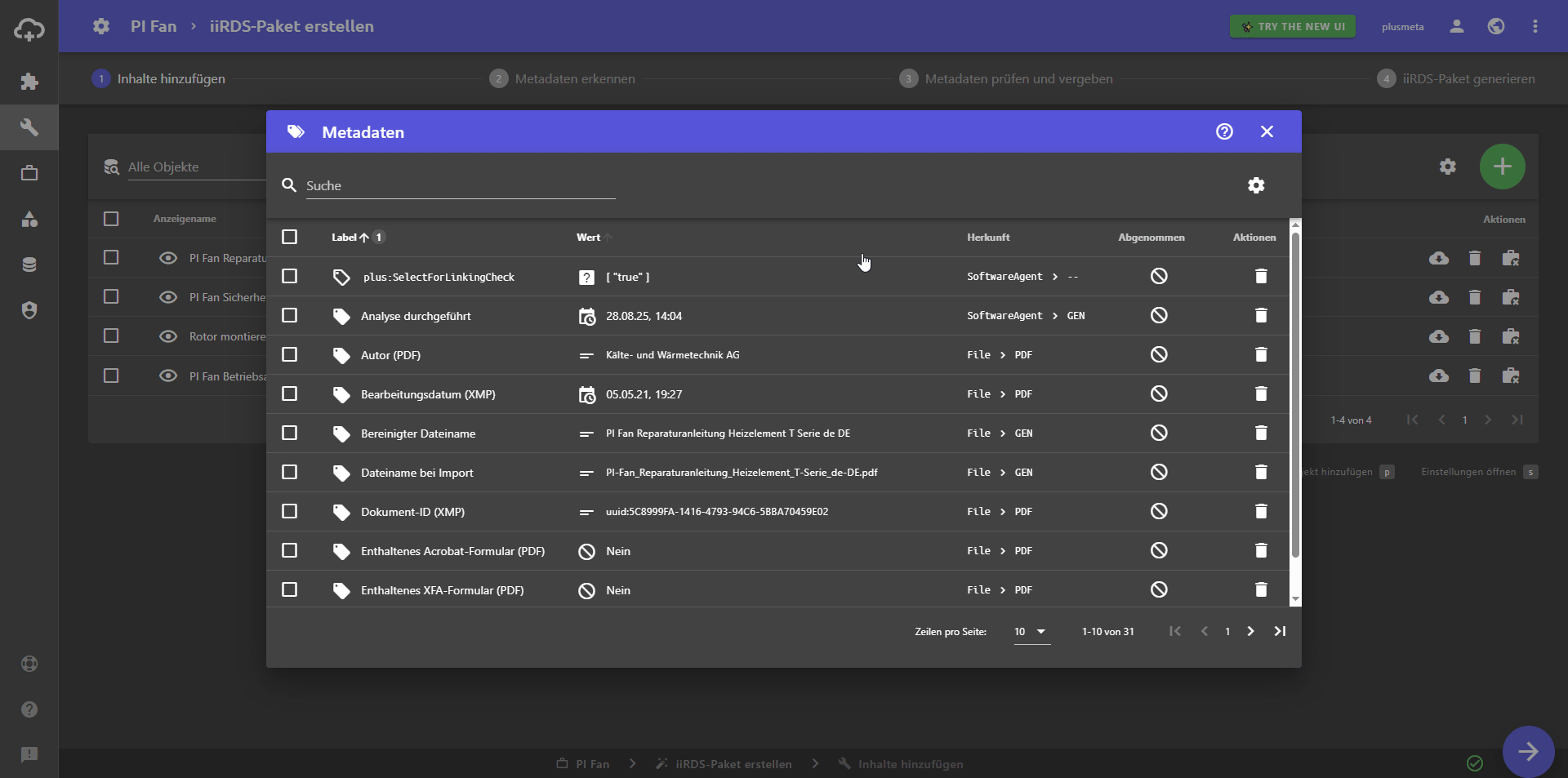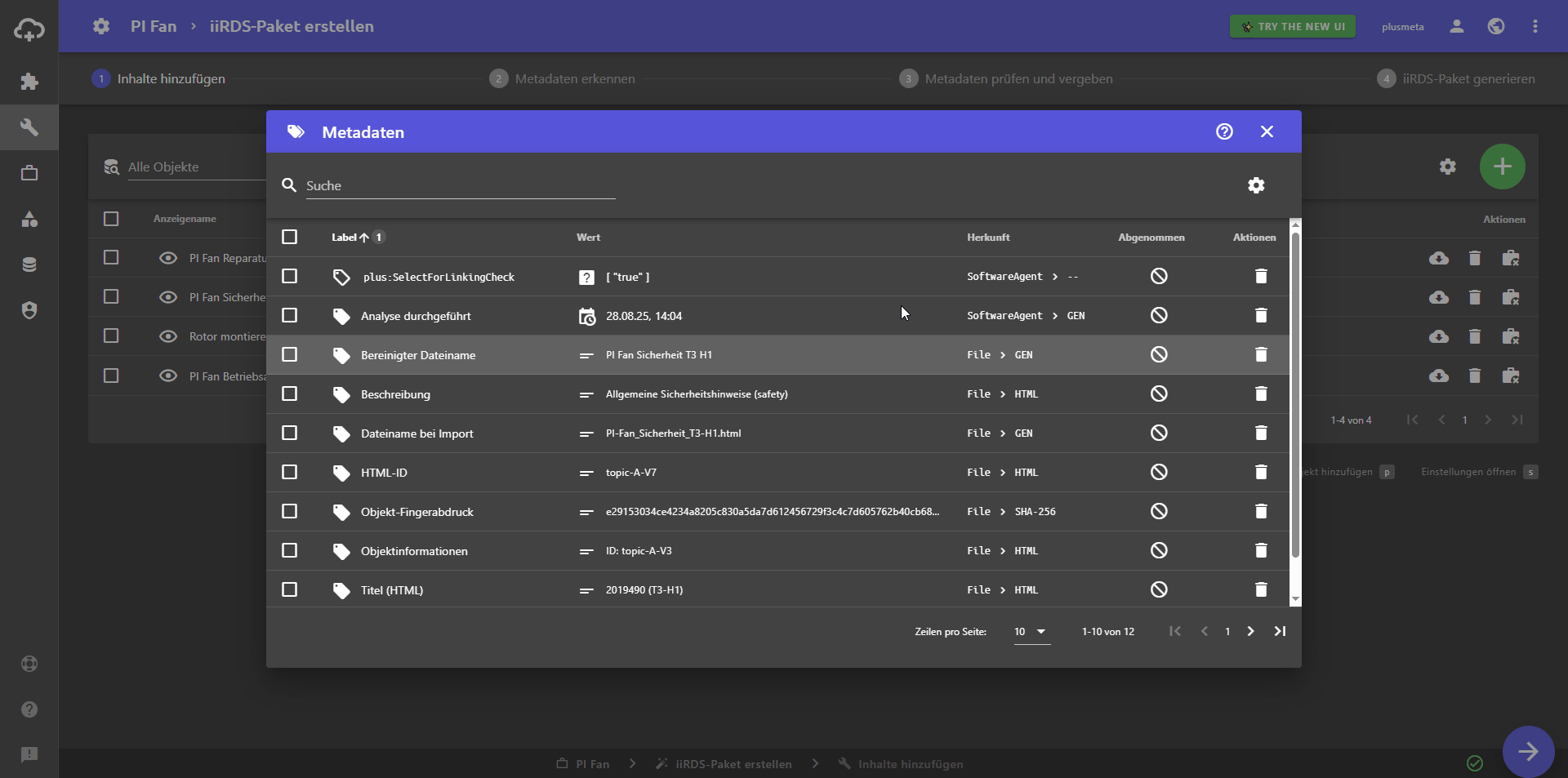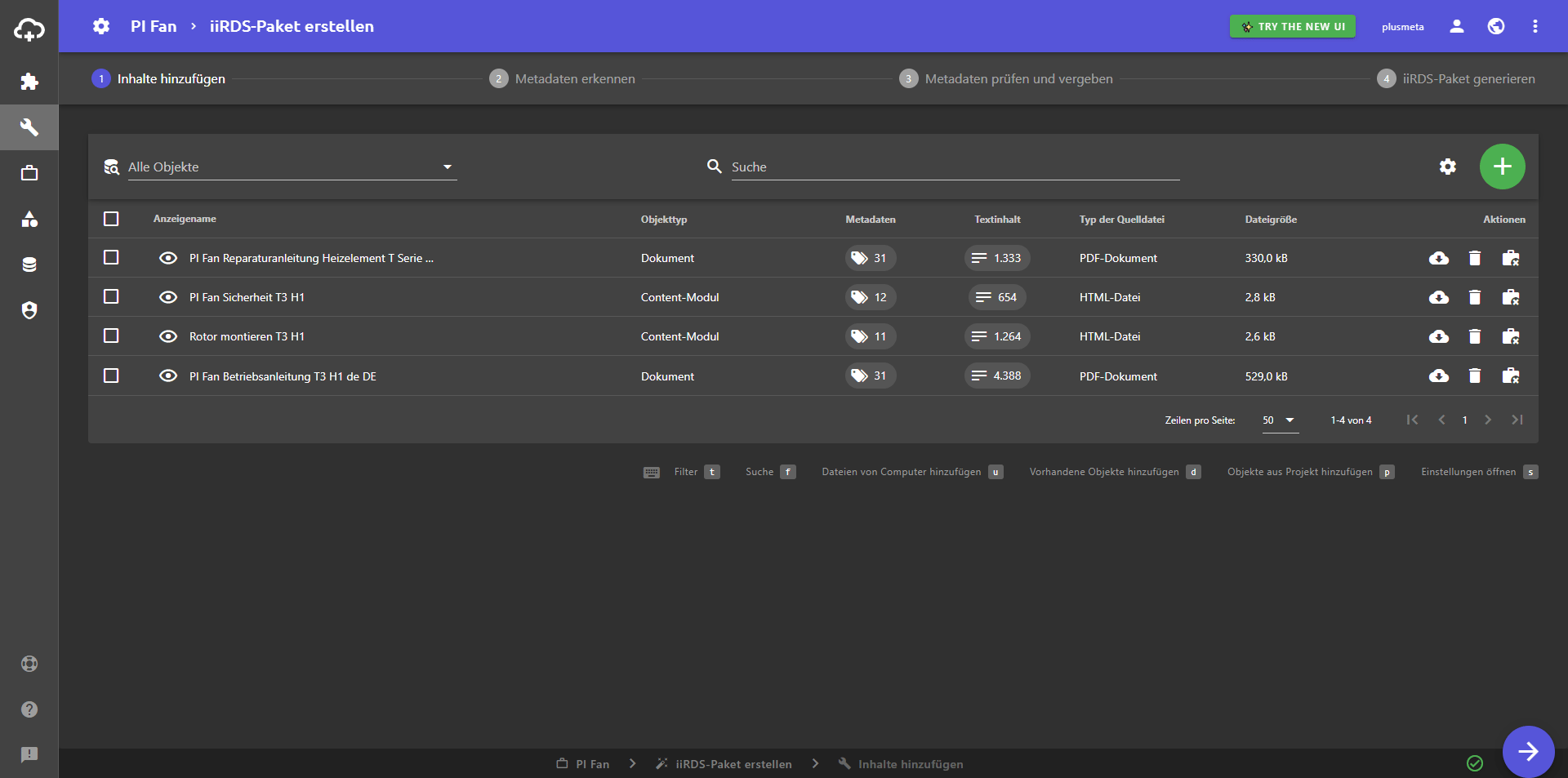
Die Spalte Metadaten wird in der Tabellenansicht angezeigt. - Auf das Feld Metadaten klicken.
Der Metadaten-Dialog öffnet sich - Im Dialog werden nun alle bereits vorhandenen Metadaten sowie deren Identifikatoren angezeigt.
Vorhandene Metadaten im Workflow-Schritt: Metadaten prüen und vergeben
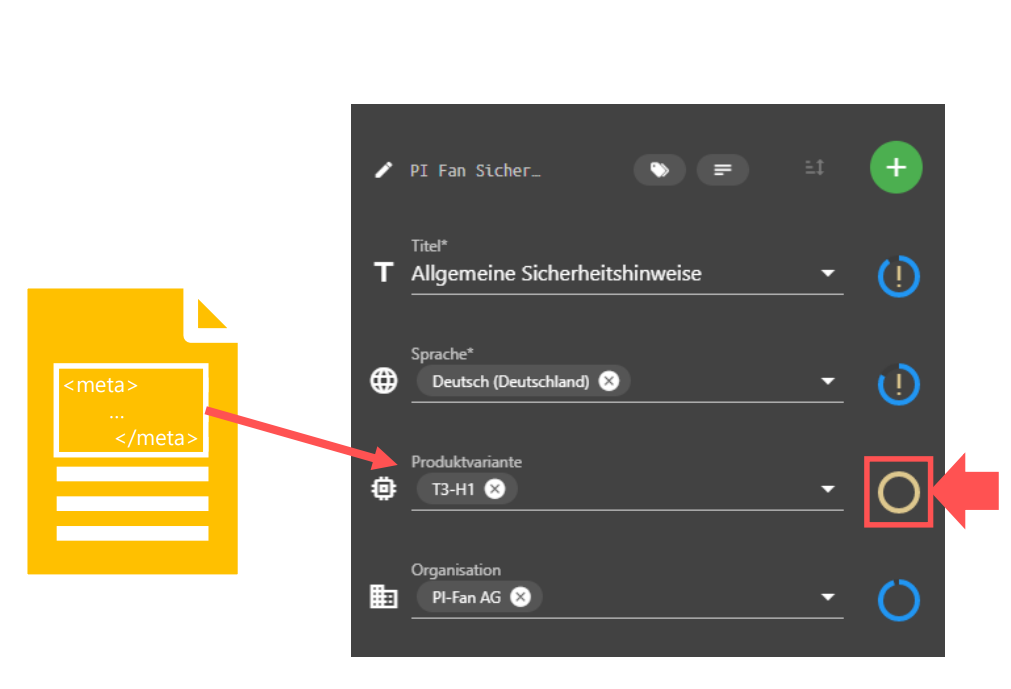
Die bereits vorhandenen Metadaten können anhand der Metadaten-Indikatoren im Workflow-Schritt Metadaten prüfen und vergeben eingesehen werden. Der beige Kreis neben dem Metadatum zeigt an, dass dieses Metadatum bereits im Objekt hinterlegt war und eingelesen wurde.
Voraussetzungen
- Listenwerte müssen in plusmeta konfiguriert sein.
- Identifikatoren müssen identisch sein.
Info: Diese Vergabemethode überlagert alle anderen Vergabemethoden (außer Projektvorgaben).