Content of this topic
- Overview of the extraction methods
- Linguistic procedures (LG / L2)
- Rule-based extraction (RB)
- Mapping (MP)
- Machine learning (ML)
- Extractor (EX)
The artificial intelligence in plusmeta is composed of different methods for metadata extraction. For every metdata, the appropriate method can be selected by configuration. The methods can also be combined.
Overview of the extraction methods
| Abbreviation | Label | Description |
|---|---|---|
| LG | Linguistic procedure | Special method for recognizing the language. |
| L2 | Linguistic procedure 2 | New concept for language recognition. Supports more languages than LG and often produces more accurate results. |
| RB | Rules-based extraction | Extraction based on rules on indicators found in the text. |
| MP | Mapping | Extraction via defined relations between metadata (knowledge graph). |
| ML | Machine learning | Prediction of metadata using a trained AI model. |
| EX | Extractor | Value extraction based on defined patterns. |
| HE | Heuristic extraction | Special procedure for determining the assumed HTML or PDF title. |
| GL | Project guidelines | Metadata that is to be assigned to all objects in the project can be defined in the guidelines in the project settings. |
| - | Imported metadata | Metadata already present in the source file is imported if there is a matching configuration in plusmeta. |
The following sections briefly explain how the main extraction methods work.
Linguistic procedures (LG / L2)
The linguistic methods are used exclusively for the recognition of languages. plusmeta offers two specific procedures, which can be selected via a configuration object.
Rule-based extraction (RB)
In rule-based extraction, the text is matched with the list of values defined in the metadata. If a match is found, points are awarded. The highest scoring match is selected and gets assigned to the object.
How many points are awarded depends on where the match was found. In addition to the names (labels) of the list values, indicators can also be specified. In addition, partial and fuzzy matches can also receive points.
There are default values in plusmeta for the points awarded. However, they can also be configured individually.
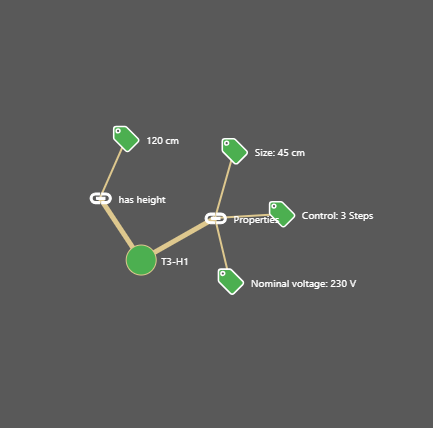
Mapping (MP)
Mappings define a knowledge graph with dependencies between metadata. This knowledge graph can be evaluated based on rules and used for metadata extraction: If a certain value “A” has been extracted as metadata, then the dependent value “B” should also be extracted.
One example is the dependent relationship between the metadata “Product” and “Manufacturer”. The dependencies can be used to express which manufacturer produces which products. If for example a product (e.g. “T3-B”) is extracted from the text, the manufacturer (e.g. “PI-Fan AG”) will also be assigned.
This way, the product features of product variants can be extracted or different metadata concepts can be mapped to other ones.
Machine learning (ML)
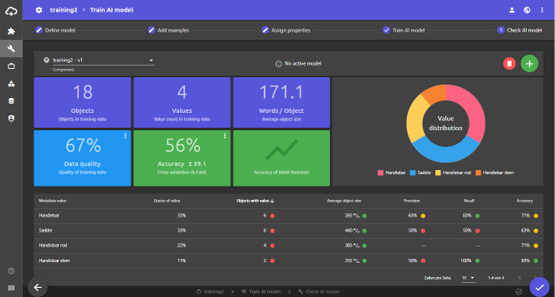
In machine learning, the metadata is extracted on the basis of a trained model. A model is needed for each metadata. In plusmeta there is a special workflow that guides you through the model training process.
A critical minimum quantity of approx. 20 examples is required to be able to create a functioning model. During training, the AI is given manually classified examples. The model is created in the background. This model is then used by plusmeta for metadata assignment.
At the end of training, the quality and accuracy of the model are scored using key data:
Extractor (EX)
Extractors use pattern matching to extract metadata. A regular expression is used to define a search pattern, e.g. a specific character string and format: “Serial number: xx-xxx-xxx”.
plusmeta searches the text for passages that match the pattern and extracts the specified part, e.g. 12-345-678, and writes it into the metadata field.
Extractors are setup via a configuration on the metadata and a configuration object.