Content of this topic
Grundlagen
Die meisten Verfahren in plusmeta funktionieren auf Basis von Text. Es kann vorkommen, dass zu verarbeitende Objekte wie eingescannte Papierdokumente oder Bilder keinen Textinhalt haben und somit nicht sinnvoll verarbeitet werden können. Mithilfe der Zeichenerkennung in plusmeta kann der Textinhalt aus solchen Objekten extrahiert werden.
Weitere Vorverarbeitungsprozesse in plusmeta werden hier erklärt.
Zeichenerkennung nutzen
Info: Blenden Sie die Spalte Textinhalt über das Zahnradmenü ein, falls noch nicht geschehen.
- Ein Projekt in der Workflows-Ansicht oder in der Projekte-Ansicht erstellen.
- Gescannte PDF-Dokumente oder Bild-Dateien über die Hinzufügen-Schaltfläche hinzufügen.
Tipp: Weitere Informationen zum Thema Objekte hinzufügen finden Sie hier.
- Die Objekte einzeln über den Kippschalter Für für Zeichenerkennung auswählen oder alle über das Zahnradmenü im Bereich Aktionen .
- Über die Schaltfläche in den nächsten Workflow-Schritt gehen. Der erkannte Textinhalt wird automatisch in das Originalobjekt geschrieben.
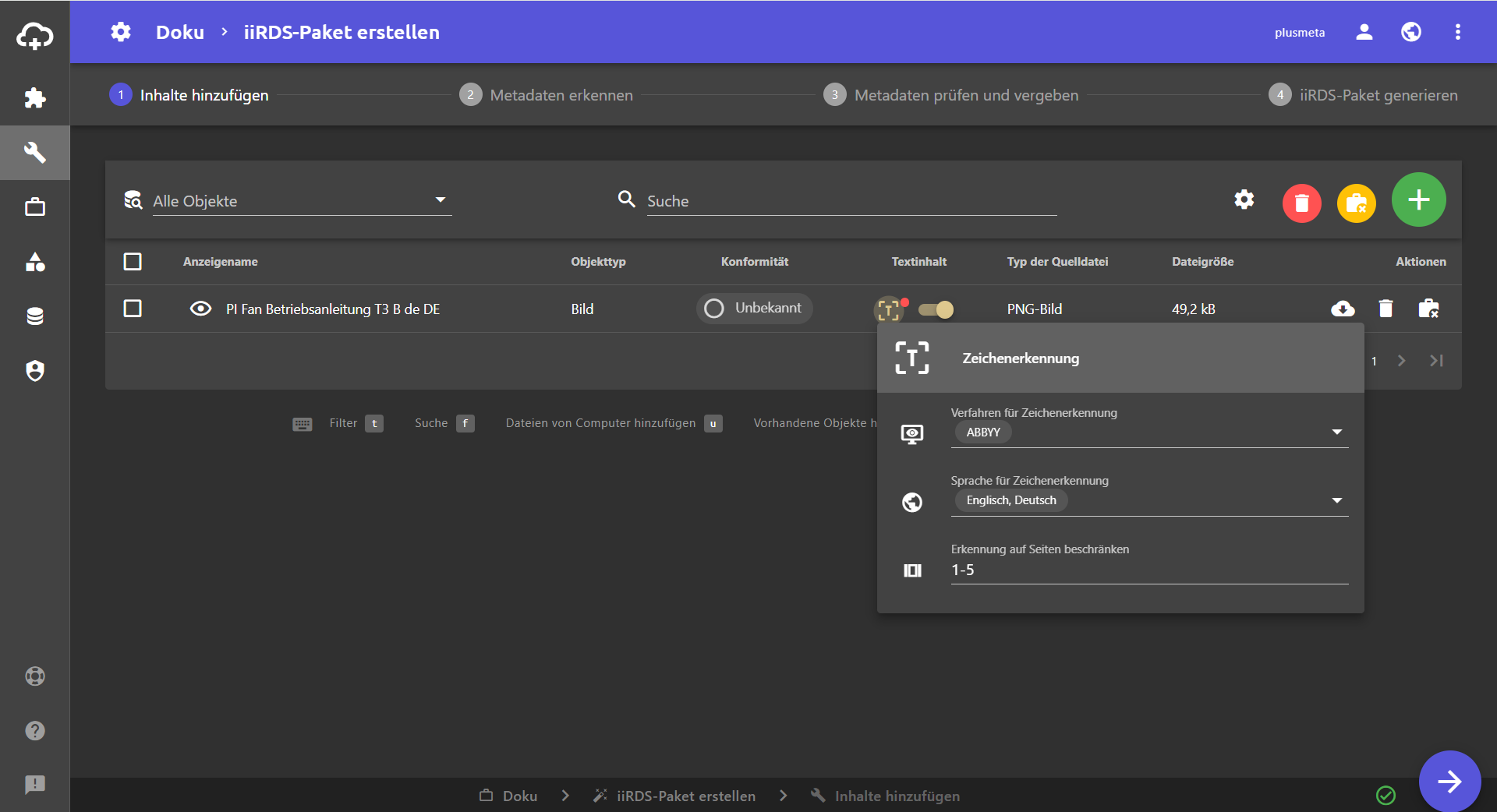
Einstellungen Zeichenerkennung
Info: Blenden Sie die Spalte Textinhalt über das Zahnradmenü ein, falls noch nicht geschehen.
Auf klicken, um die Einstellungen für Zeichenerkennung anzupassen.
- Verfahren für Zeichenerkennung:
- ABBY
- AWS Textract
- Profile für Zeichenerkennung:
- Englisch, Deutsch
- Englisch, Deutsch, automatisch gedreht
- Französich
- etc.
- Erkennung auf Seiten beschränken:
- z.B. 1-5, 8, 11-13
- kann auch in den Projekteinstellung des jeweiligen Workflows angepasst werden